

Para modelos de linguagem grandes, maior é melhor (e mais rápido), mas melhor é melhor. E um dos principais insights que a equipe de pesquisa da Meta AI obteve com a família de modelos Llama é que qualquer modelo otimiza para inferência de IA de menor custo e melhor desempenho e, em seguida, elimina ineficiências que podem surgir do treinamento de IA com as quais desejo lidar. esse.
E agora, com o Llama 3, a plataforma Meta melhorou o treinamento e a inferência de IA para executar os modelos mais recentes do Google Gemini Pro 1.5, Microsoft/OpenAI GPT-4 e Anthropic Claude 3. dinheiro Mas isso ainda está para ser visto.
O modelo original do Llama 1, como o chamamos agora, foi anunciado há muito tempo, em fevereiro de 2023. Detalhamos como o Llama é diferente de todos os principais LLMs da época e continuaremos a fazê-lo. Para rever tudo de novo. Você pode ler um artigo que descreve quatro modelos Llama diferentes e os conjuntos de dados de código aberto usados para treiná-los neste link. Embora o modelo Llama 1 não fosse de código aberto, a Meta Platforms forneceu o código-fonte aos pesquisadores que se inscreveram, e esperava-se que o Llama fosse eventualmente lançado publicamente.
Com o Llama 1, a Meta Platforms oferece modelos com significativamente menos parâmetros: 7 bilhões, 13 bilhões, 33 bilhões e 65 bilhões, comparáveis ou comparáveis aos modelos muito maiores GPT-3 175B e PaLM 540B da OpenAI e da OpenAI. que. Google. Os resultados iniciais mostraram o que deveria ser óbvio para todos. Mais dados são melhores do que mais parâmetros.
Você notará que isso é apenas uma consequência do que reformulamos a seguir. Mais dados sempre superam algoritmos melhoresEsta é uma citação de uma ideia apresentada por Peter Norvig, professor da Universidade de Stanford e pesquisador e diretor de engenharia do Google há mais de 20 anos, e coautor deste artigo seminal. Validade irracional dos dados Em 2009.
O que é importante no Llama é que a metaplataforma se concentrou na redução dos custos de inferência e na melhoria do desempenho da inferência. O modelo Llama também foi contra a sabedoria convencional dos criadores do Chinchilla LLM de que existe um tamanho de modelo ideal, orçamento computacional e número de tokens. , tempo de treinamento, latência de inferência, desempenho. A Meta Platforms pegou o menor modelo com 7 bilhões de parâmetros e colocou mais de 1 trilhão de tokens nele. Llama 1 7B continuou a melhorar em comparação com a ruminação com menos fichas. O modelo Llama 1 foi treinado em 2.048 GPUs A100 “Ampere”, com os modelos 7B e 13B usando 1 trilhão de tokens, e os modelos 33B e 65B usando 1,4 trilhão de tokens. A extensão do contexto, ou a quantidade de dados que poderiam ser inseridos no prompt da Llama 1, era de apenas 2.048 tokens.
Llama 2 lançado em julho de 2023 não contém mais nota de resgate. Não LLaMA. Significa Large Language Model Meta AI, que é tecnicamente LLMMAI, mas quem está monitorando isso? Hoje em dia chamamos apenas de Llama. O modelo Llama 2 foi treinado com 2 trilhões de tokens, com variações de parâmetros de 7B, 13B e 70B, e a janela de contexto foi duplicada para 4.096 tokens. Mais de 1 milhão de anotações humanas para reduzir erros e ilusões, aumentando a precisão do teste em vários pontos. (Você pode ler o artigo do Llama 2 aqui.) É importante ressaltar que o modelo do Llama 2 foi adequado e totalmente de código aberto e gratuito para pesquisa e uso comercial. É por isso que acreditamos que, no longo prazo, a estrutura PyTorch e os modelos Llama serão amplamente utilizados por empresas que desejam implementar sua própria IA.
Na semana passada, a Meta Platforms revelou o Llama 3 e sua interface de bate-papo Meta AI aprimorada. Essa interface está integrada nos aplicativos do Facebook, Instagram, WhatsApp e Messenger e atualmente é baseada no Llama 3.
No Llama 3, o modelo vem com variações de parâmetros de 8B e 80B. Até agora, as metaplataformas resistiram à tentação de criar modelos paramétricos 800B para manter a computação inferencial e os custos baixos. E foi treinado contra impressionantes 15 trilhões de parâmetros. símbolo. Mais de 5% dos seus dados de treinamento (ou aproximadamente 800 milhões de tokens) representavam dados em 30 idiomas diferentes. A Meta Platforms também não revelou o número de tokens nesta área, mas disse que quatro vezes a quantidade de código (ou seja, código de linguagem de programação) foi usada no treinamento do Llama 3 em comparação ao Llama 2. Ta. (Eu me pergunto onde a Meta Platforms mantém esse código.) Curiosamente, o modelo Llama 2 analisa esses trilhões de tokens para identificar o conjunto de dados apropriado para adicionar ao treinamento para o qual o Llama 3. foi usado. O código-fonte e os dados de treinamento do Lama3 estão disponíveis aqui no GitHub e aqui no Hugging Face. Pesos de modelo e tokenizadores estão disponíveis diretamente na metaplataforma.
A Meta Platforms sugeriu no anúncio que outros números de parâmetros estarão disponíveis para os modelos Llama 3 no futuro, portanto, não consideramos modelos maiores ou menores no futuro. A Meta Platforms ainda não divulgou a documentação técnica do Llama 3, mas o anúncio contém algumas informações interessantes.
“De acordo com nossa filosofia de design, escolhemos uma arquitetura de transformador somente decodificador relativamente padrão para o Llama 3”, escreveram dezenas de pesquisadores que trabalham no LLM em um blog de anúncio anunciando o Llama 3. Masu. Fiz algumas melhorias importantes. O Llama 3 usa um tokenizer com um vocabulário de 128.000 tokens que codifica a linguagem de forma mais eficiente, o que melhora significativamente o desempenho do modelo. Para melhorar a eficiência de inferência do modelo Llama 3, empregamos Grouped Query Attention (GQA) nos tamanhos 8B e 70B. Treinamos o modelo em uma sequência de 8.192 tokens, usando uma máscara para evitar que a autoatenção cruzasse os limites do documento. ”
Existem variações maiores do Llama 3 na metaplataforma, com a maior tendo mais de 400 bilhões de parâmetros. Esses recursos se somam a outros recursos que ainda não estão prontos para o horário nobre, mas fazem parte da pilha do Llama 3, como a capacidade de realizar processamento multimodal, falar em vários idiomas e ter janelas de contexto maiores, acho que serão. anunciado ao mesmo tempo. (Supostamente ainda são 4.096 tokens, semelhantes ao Llama 2, mas a Meta Platforms não disse isso no anúncio. Perguntei ao chatbot Meta AI e eles disseram que eram de fato 4.096 tokens.)
O modelo Llama 3 foi treinado em um par de clusters baseados em GPUs Nvidia “Hopper” H100. Um usa Ethernet e o outro usa InfiniBand. Falamos sobre isso em detalhes aqui no mês passado, e cada um possui 24.576 GPUs. De acordo com a Meta Platforms, a implementação mais eficiente do Llama 3 foi executada em 16.000 GPUs, e todos os tipos de ajustes no sistema tornaram o treinamento 3x mais eficiente do que o Llama 3. No entanto, a utilização computacional atingiu apenas 400 teraflops por GPU nessas 16.000 GPUs. Rodando com meia precisão FP16 com dispersão desativada, o H100 é avaliado em 989 teraflops, resultando em apenas 40,4% de eficiência computacional. Quando o H100 executando o Llama 3 tem o suporte à dispersão habilitado ou o formato dos dados tem precisão de 1/4 do FP8, a eficiência computacional é de apenas 20,2%. Além disso, o FP8 com dispersão ativada tem uma eficiência computacional de apenas 10,1%.
Compare o Llama 3 7B e 70B com outros modelos que operam no modo “instrução”, onde você precisa fazer algo como fazer um teste ou fazer contas, bem como Google Gemma e Gemini Pro 1.5, Mistral e Claude 3. Mostrado abaixo .
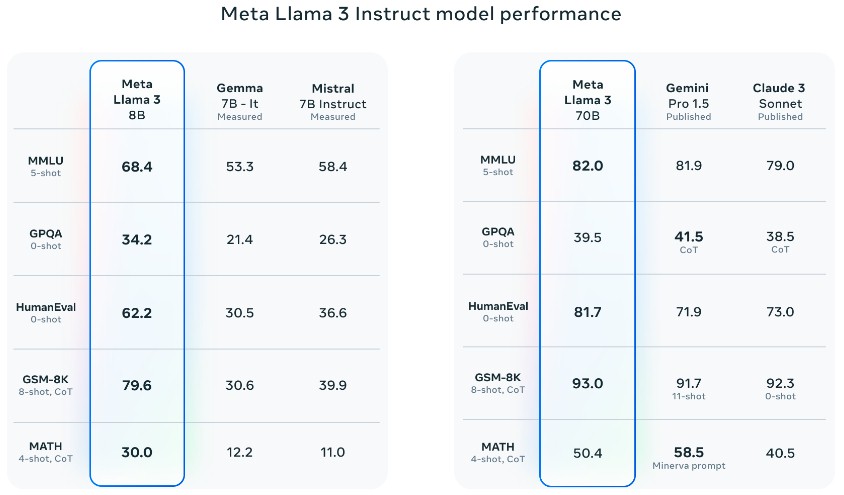

O benchmark acima é o benchmark Massive Multitask Language Understanding que testa o tratamento de contexto. Testes de múltipla escolha com perguntas e respostas à prova do Google em nível de pós-graduação em biologia, física e química. Teste de geração de código HumanEval. Teste de matemática do ensino fundamental GSM-8K. e um teste de problema de palavras matemáticas.
Veja como o Llama 3 LLM pré-treinado se compara a outros modelos pré-treinados em cinco benchmarks diferentes.

AGIEval English é uma combinação de vestibulares. BIG-Bench Hard é uma série de quebra-cabeças lógicos que testam seu raciocínio de bom senso. ARC-Challenge é um corpus de raciocínio abstrato baseado em padrões simétricos complexos. DROP significa “Raciocínio Discreto sobre o Conteúdo do Parágrafo'' e é um teste de compreensão de leitura.
A Meta Platforms reiterou que deseja manter seus modelos pequenos e executar grandes quantidades de dados através deles. Isto leva mais tempo e cálculo, mas acaba por dar melhores resultados, mesmo que os custos de formação sejam mais elevados. Isso significa custos de inferência mais baixos, o que é mais importante para pilhas de aplicativos de metaplataforma.
“Durante o desenvolvimento do Llama 3, fizemos várias novas observações sobre o comportamento de escalonamento”, escreveram os engenheiros da Meta Platforms. “Por exemplo, embora a quantidade ideal de cálculo de treinamento do Chinchilla para um modelo de parâmetro de 8B seja equivalente a aproximadamente 200B de tokens, descobrimos que o desempenho do modelo continuou a melhorar mesmo depois que o modelo foi treinado em duas ordens de magnitude a mais de dados. continuou a melhorar log-linearmente após o treinamento de até 15T tokens. Os modelos maiores corresponderam ao desempenho desses modelos menores com menos cálculos de treinamento, mas foram mais eficientes durante a inferência.
E só para se divertir um pouco, a Meta Platforms mostrou o desempenho do benchmark Llama 3 em um benchmark pré-treinado com mais de 400 bilhões de parâmetros.

Aqui está o problema. O modelo pré-treinado no Llama 3 8B tem uma média de notas de 62,1 por cento, que é nosso ponto de partida de F. O Llama 3 70B teve um bom desempenho com uma nota média de 79,3%, mas ainda assim obteve uma média de apenas C+. Você não pode entrar em uma boa universidade com esse GPA. Modelo Pré-treinado Llama 3 400B+ – Este modelo ainda está em treinamento, então não há dúvidas sobre sua nota. Além disso, o número de parâmetros que esta variante do Llama 3 tem mais de 400 bilhões é desconhecido, portanto, não faça suposições. É 400B, muito provavelmente 800B. LLM obteve um GPA de 83,9 nesses cinco testes, um sólido B. Sim, modelos menores são executados mais rapidamente na inferência, mas modelos claramente maiores têm melhor pontuação.
Qual você gostaria de incorporar em seu próprio aplicativo ou nas pessoas ou empresas com as quais você faz negócios (sabemos que a resposta pode estar no LLM).
E aqui está uma boa pergunta: Onde posso encontrar Red Hat para PyTorch e Llama? Llama teve mais de 30 milhões de downloads de fevereiro a setembro de 2023, 10 milhões dos quais foram baixados somente em setembro. Nesse ritmo, se o número de downloads continuar em linha reta de setembro do ano passado até agora, o Llama já teria ultrapassado aproximadamente 100 milhões de downloads.
Serão realmente IBM watsonx, Red Hat Enterprise Linux, OpenShift para contêineres Kubernetes e OpenStack para gerenciamento de virtualização de cluster subjacente. Novos players surgirão? Alguém quer começar um novo negócio?
Não seria estranho se a IBM vendesse toneladas de software e suporte graças à IA que gera. O WebSphere é um poderoso servidor web Apache com servidor de aplicativos Java Tomcat integrado e tem sido um ótimo complemento para a IBM no passado? 25 anos, trouxe uma receita desconhecida de dezenas de bilhões de dólares, talvez metade dos quais, e caiu no fundo.