



A IA generativa (GenAI) é uma das primeiras tecnologias da história. Mas para que seja seriamente considerado pelos conselhos de administração e líderes empresariais, deve provar o seu valor em casos de utilização empresarial. Como você pode aumentar a velocidade dos negócios, da inovação e das operações?
A Pure Storage está colaborando com a NVIDIA para aprimorar o poder do GenAI para aplicativos empresariais de IA usando geração aumentada de pesquisa (RAG), com uma demonstração ao vivo esta semana no NVIDIA GTC. Aqui detalhamos como usar RAG para casos de uso de Large Language Model (LLM) de grande escala e alto desempenho.
Valor RAG
O RAG permite que as empresas melhorem e personalizem o LLM geral com fontes de dados externas, mais específicas e proprietárias. Isso resolverá rapidamente suas principais preocupações da GenAI e tornará seu LLM mais preciso, oportuno e relevante, consultando nossa base de conhecimento. fora Foi para isso que fui treinado.
Uma das principais preocupações é que alucinação, um problema que o LLM pode enfrentar, resultando na produção de respostas plausíveis, mas errôneas. O raciocínio incorreto pode resultar em análises econômicas, negociações ou recomendações de investimento inadequadas. Isso pode dificultar o uso da tecnologia em ambientes reais onde a precisão é crítica para os negócios. A implantação do RAG reduz o risco de ilusões e fornece aos analistas melhores insights para a ação.
Outra preocupação é que o LLM não pode: Incorporar novos dados Estará disponível após o treinamento inicial do modelo e mesmo após o treinamento subsequente. Os RAGs podem incorporar facilmente os dados e conhecimentos corporativos mais recentes em consultas e respostas, eliminando a necessidade de retreinar regularmente os LLMs.
Consideremos o setor de serviços financeiros altamente regulamentado, onde a fiabilidade, a precisão e a oportunidade são críticas. Aprimorar o LLM de finanças gerais com bancos de dados de vetores proprietários e de clientes específicos pode aumentar a capacidade de uma instituição financeira de treinar seu próprio LLM. Dados externos de demonstrações financeiras corporativas, relatórios de corretores, registros de conformidade e bancos de dados de clientes podem fornecer análises mais específicas e significativas, permitindo que bancos, empresas comerciais e de investimento atendam melhor seus clientes. Os sistemas de IA serão capazes de gerar insights de investimento oportunos e fortalecer a conformidade. . Valide fontes de dados e reduza riscos.
Além disso, construir e treinar seu próprio LLM é caro. O RAG ajuda as empresas a economizar custos e recursos significativos, tornando o GenAI mais aplicável às empresas, especialmente do ponto de vista do retorno do investimento.
Exemplo: Construindo uma base de conhecimento com IA
Outro caso de uso da indústria é: Fabricantes que desejam usar documentação de produtos, bases de conhecimento de suporte técnico, vídeos do YouTube e comunicados de imprensa para criar um sistema de conhecimento baseado em IA que gere respostas úteis e precisas para seus funcionários. As respostas geradas por IA limitadas a 9 meses de dados públicos são limitadas demais para serem valiosas e você não pode consultar a documentação ou os vídeos dos produtos da própria empresa.
Quando aplicados com RAG, os sistemas de conhecimento fornecem aos clientes e funcionários acesso a informações atualizadas para referência e treinamento, proporcionando muitas oportunidades para a IA melhorar os processos operacionais, de vendas e de suporte.
Pure Storage se une à NVIDIA para trazer geração de expansão de pesquisa para empresas
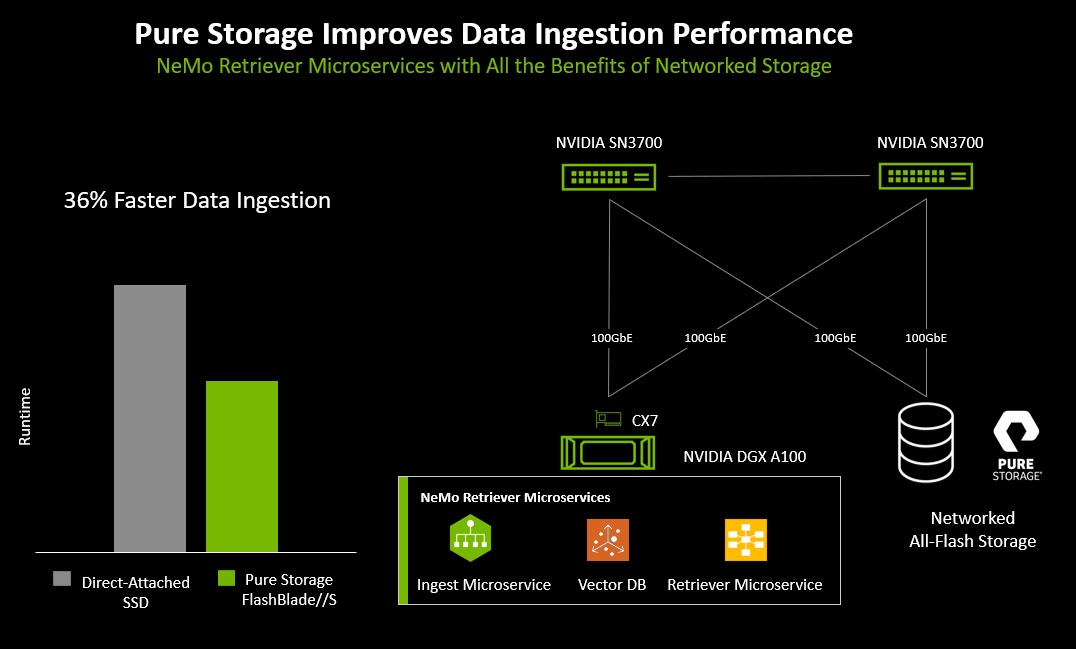
Para simplificar e acelerar o processo RAG, a Pure Storage está trabalhando com a NVIDIA para demonstrar o pipeline RAG para inferência de IA e simular casos de uso corporativo. Isso complementa os novos microsserviços NVIDIA NeMo Retriever anunciados hoje no NVIDIA GTC, que estarão disponíveis para IA de nível de produção usando o pacote de software NVIDIA AI Enterprise.
Veja como funciona: As GPUs NVIDIA são usadas para computação, e o Pure Storage® FlashBlade//S™ fornece armazenamento empresarial totalmente flash para grandes bancos de dados vetoriais e seus dados brutos associados. Neste caso, os dados brutos consistem em uma grande coleção de documentos públicos, típicos de repositórios de documentos públicos ou privados utilizados para RAGs.
O RAG melhora a precisão e a relevância da inferência LLM, tomando dados limpos e vetorizados (documentos novos ou exclusivos) como entrada e fornecendo uma pesquisa vetorial da consulta ao modelo. Isso fornece melhor orientação para a entrada de parâmetros no LLM e ajusta a saída para o usuário.
O resultado é Melhore a precisão, a atualidade e a relevância das consultas de inferência do LLM Para as organizações, torna-se mais conveniente para os clientes finais em casos de uso de resposta a perguntas e resumo de documentos.
Por que usar RAG com Pure Storage?
O Pure Storage FlashBlade//S se destaca por fornecer o desempenho multidimensional necessário para cargas de trabalho RAG exigentes. Uma plataforma de armazenamento compartilhado eficiente e de alto desempenho para bancos de dados vetoriais, análises, documentos brutos para incorporação, modelos de IA e dados de log.
Por que isso é importante:
- Taxa. Nas implantações GenAI RAG, o tamanho do banco de dados de vetores ultrapassa dezenas de milhões de vetores, tornando seu custo proibitivo para caber na memória da GPU. Outro método é armazenar o banco de dados vetorial em armazenamento local no servidor. No entanto, existem limites para o desempenho, a eficiência e a escala de uma empresa.
- desempenho. Quando há vários armazenamentos de documentos e centenas ou milhares de usuários de IA, o LLM aprimorado por RAG é executado em vários servidores GPU e precisa compartilhar armazenamento escalonável para fins de treinamento/incorporação e inferência/recuperação. Uma solução GenAI RAG de grande empresa possui vários servidores que incorporam e indexam simultaneamente novos documentos, bem como recuperam documentos e executam consultas LLM. Isso significa que o armazenamento deve ter recursos de desempenho multimodal que suportem uma combinação fixa de leituras e gravações de um grande número de servidores.
- escala. O dimensionamento adicional à medida que seus dados crescem é simplificado com desempenho e acréscimos de capacidade fáceis e sem interrupções. Não é de surpreender que o uso de uma solução de armazenamento de rede empresarial como o Pure Storage FlashBlade//S forneça proteção de dados mais forte, melhor compartilhamento de dados, gerenciamento mais fácil e melhor compartilhamento de dados do que o armazenamento local dentro de cada servidor de IA. e provisionamento mais flexível. Também melhora o desempenho ao incorporar e indexar grandes armazenamentos de documentos.
Quão rápido é rápido?
A Pure Storage realizou testes de escalabilidade de incorporação e indexação do GenAI RAG. Os testes abrangem dois servidores GPU NVIDIA (servidores incorporados) e dois servidores X86 (nós de índice) com armazenamento flash local com interface de armazenamento de objetos padrão e um Pure Storage FlashBlade //S totalmente preenchido foi comparado usando.
Testamos três estágios diferentes do processo de incorporação e indexação de documentos.
- Carregar arquivos vetoriais para armazenamento de objetos
- Inserção em massa de vetores em um banco de dados de vetores
- Criando e gravando arquivos de índice
Os resultados demonstram que executar o processo RAG em dois nós (dois servidores e dois nós de índice) é significativamente mais rápido do que usar apenas um nó, e que o RAG pode ser dimensionado em vários nós.
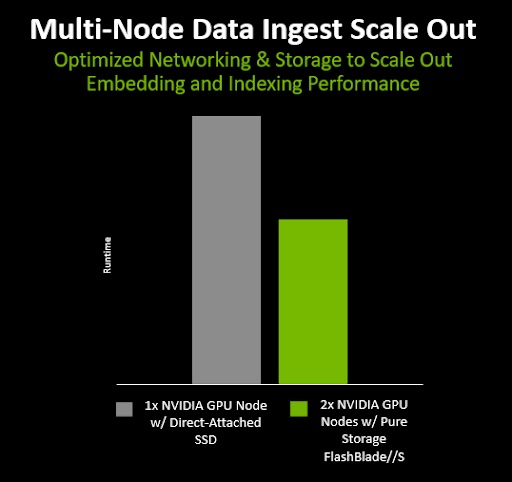
A incorporação e indexação de documentos também foram concluídas 36% mais rápido usando Pure Storage FlashBlade//S com sua interface S3 nativa do que usando SSDs locais em cada servidor. Isso mostra que o armazenamento rápido totalmente flash conectado à rede pode ajudar a acelerar a incorporação de documentos RAG.
Benefícios para o cliente
Esse pipeline RAG processa um repositório inteiro de documentos em um banco de dados vetorial em segundos com a ajuda do LLM e um pipeline RAG com GPUs NVIDIA, rede NVIDIA, microsserviços NVIDIA e Pure Storage FlashBlade//S. Demonstramos que podemos fazer consultas. Isso é poderoso porque os resultados retornados são baseados nas ricas informações do banco de dados vetorial e nos recursos de geração do LLM.
Pure Storage FlashBlade//S serve como armazenamento empresarial rápido e eficiente em log, bancos de dados vetoriais, análises e dados brutos com desempenho multidimensional. A capacidade de adicionar blades de módulos DirectFlash® sem interrupções para aumentar o desempenho e a capacidade proporciona agilidade para atender aos requisitos crescentes de dados de streaming multimodais e em tempo real. Isso o torna uma solução ideal para empresas que adicionam LLM e RAG aos seus processos de negócios de produção.
Para saber mais sobre como a Pure Storage pode acelerar sua adoção de IA, visite nossa página de soluções de IA e entre em contato com nossa equipe de vendas.
O artigo original é aqui.
As opiniões e opiniões expressas neste artigo são de responsabilidade do autor e não refletem necessariamente as da CDOTrends. Crédito da imagem: iStockphoto/Ksenia Zvezdina