



Créditos da imagem: Haje Kamps / Meio da Jornada
Acompanhar um setor em rápida mudança como a IA é um desafio. Então, até que a IA possa fazer isso por você, aqui está uma rápida recapitulação de histórias recentes no mundo do aprendizado de máquina, bem como pesquisas e experimentos notáveis que não poderíamos cobrir sozinhos.
Na semana passada, a Midjourney, uma startup de IA que cria geradores de imagens (e em breve vídeos), fez uma pequena mudança em seus termos de serviço, relacionada à sua política sobre disputas de propriedade intelectual. Isto serviu principalmente para substituir a linguagem irónica por disposições mais legais e possivelmente baseadas em precedentes. Mas a mudança também sinaliza a confiança de Midjourney de que fornecedores de IA como a sua empresa prevalecerão em batalhas legais com criadores cujo trabalho depende dos seus dados de formação.


Alterações nos Termos de Uso do Midjourney.
Modelos generativos de IA como Midjourney são normalmente treinados em um grande número de exemplos (como imagens e texto) extraídos de sites públicos e repositórios na web.reivindicações do fornecedor O uso justo é uma doutrina jurídica que permite o uso de obras protegidas por direitos autorais para criar obras derivadas, desde que sejam transformadoras, e as protege no que diz respeito ao treinamento de modelos. Mas nem todos os criadores concordam, especialmente tendo em conta o crescente conjunto de pesquisas que mostram que os modelos podem e realmente “regurgitam” dados de treinamento.
Alguns fornecedores estão adotando uma abordagem proativa, como celebrar acordos de licenciamento com criadores de conteúdo e estabelecer esquemas de “exclusão” para conjuntos de dados de treinamento. Algumas empresas prometem que, se seus clientes se envolverem em uma ação judicial de direitos autorais decorrente do uso das ferramentas GenAI de um fornecedor, não serão cobradas taxas legais.
O meio da jornada não é agressivo.
Pelo contrário, Midjourney tem sido um tanto descarado quando se trata de usar obras protegidas por direitos autorais, chegando a gerenciar uma lista de milhares de artistas, incluindo ilustradores e designers de grandes marcas como Hasbro e Nintendo, e a obra foi ou será usada. para treinamento. Modelo de meio de viagem. A investigação mostrou evidências convincentes de que Midjourney usou séries de televisão e filmes para dados de programação, de “Toy Story” a “Star Wars”, “Dune” e “The Avengers”.
Agora, existe um cenário em que a decisão do tribunal acaba resultando em algo como Midjourney. Mesmo que o sistema judicial decida que o uso justo se aplica, nada impede a startup de continuar normalmente e coletar e treinar dados novos e antigos protegidos por direitos autorais.
Mas isso parece uma aposta arriscada.
Midjourney está atualmente em alta, supostamente alcançando cerca de US$ 200 milhões em receitas sem usar um único centavo de investimento externo. No entanto, os advogados são caros. E se fosse determinado que o uso justo não se aplicava no caso da Midjourney, a empresa seria destruída da noite para o dia.
Não há recompensa sem risco, certo?
Aqui estão algumas outras histórias notáveis de IA dos últimos dias.
Anúncios baseados em IA atraem o tipo errado de atenção: Os criadores do Instagram ficaram indignados com um diretor que reutilizou o trabalho de outra pessoa (muito mais difícil e impressionante) sem crédito em um comercial.
Autoridades da UE alertam sobre plataformas de IA antes das eleições: Eles estão pedindo às maiores empresas do setor de tecnologia que expliquem suas abordagens para prevenir a fraude eleitoral.
Google Deepmind quer que IA seja sua parceira em jogos cooperativos: Ao treinar agentes com horas de jogo em 3D, eles agora podem realizar tarefas simples expressas em linguagem natural.
Problemas de referência: Muitos fornecedores de IA afirmam que seus modelos se igualam ou superam seus concorrentes por alguma métrica objetiva. Mas as métricas que eles usam costumam ser falhas.
AI2 recebe US$ 200 milhões: A AI2 Incubator foi desmembrada da organização sem fins lucrativos Allen Institute for AI e garantiu um lucro inesperado de US$ 200 milhões em financiamento de computação. As start-ups com programas implementados podem utilizar isto para acelerar o desenvolvimento inicial.
A Índia exigirá a aprovação do governo para IA e depois a reversão. O governo indiano parece incapaz de decidir qual nível de regulamentação é apropriado para a indústria de IA.
Anthropic lança novos modelos: A startup de IA Anthropic lançou uma nova família de modelos chamada Claude 3, que afirma ser comparável ao GPT-4 da OpenAI. Testamos o modelo principal (Claude 3 Opus) e descobrimos que ele é ótimo, mas também ficou aquém em áreas como eventos atuais.
Deepfakes políticos: Um estudo realizado pelo Centro de Combate ao Ódio Digital (CCDH), uma organização sem fins lucrativos do Reino Unido, descobriu que a quantidade de desinformação gerada por IA no X (antigo Twitter) aumentou ao longo do ano passado, especialmente imagens deepfake relacionadas com eleições. está sendo investigado.
OpenAI vs. máscara: A OpenAI afirma que pretende rejeitar todas as reivindicações feitas pelo CEO da X, Elon Musk, em um processo recente, sugerindo que o empresário bilionário que ajudou a co-fundar a empresa está por trás do desenvolvimento da OpenAI, sugeriu que não teve muito impacto e sucesso.
Comente Rufus: No mês passado, a Amazon anunciou a introdução de um novo chatbot com tecnologia de IA, Rufus, no aplicativo Amazon Shopping para Android e iOS. Conseguimos acesso antecipado e rapidamente ficamos desapontados com a falta de coisas que Rufus poderia fazer (e fazer bem).
Mais aprendizado de máquina
molécula! Como eles funcionam? Os modelos de IA nos ajudam a compreender e prever a dinâmica molecular, a conformação e outros aspectos do mundo em nanoescala que, de outra forma, exigiriam métodos caros e complexos para serem testados. É claro que ainda precisa ser testado, mas coisas como AlphaFold estão mudando rapidamente de campo.
A Microsoft desenvolveu um novo modelo chamado ViSNet que visa prever as chamadas relações estrutura-atividade, as relações complexas entre moléculas e atividades biológicas. Isto ainda é bastante experimental e definitivamente dirigido apenas a investigadores, mas é sempre bom ver problemas difíceis na ciência resolvidos por meios tecnológicos de ponta.

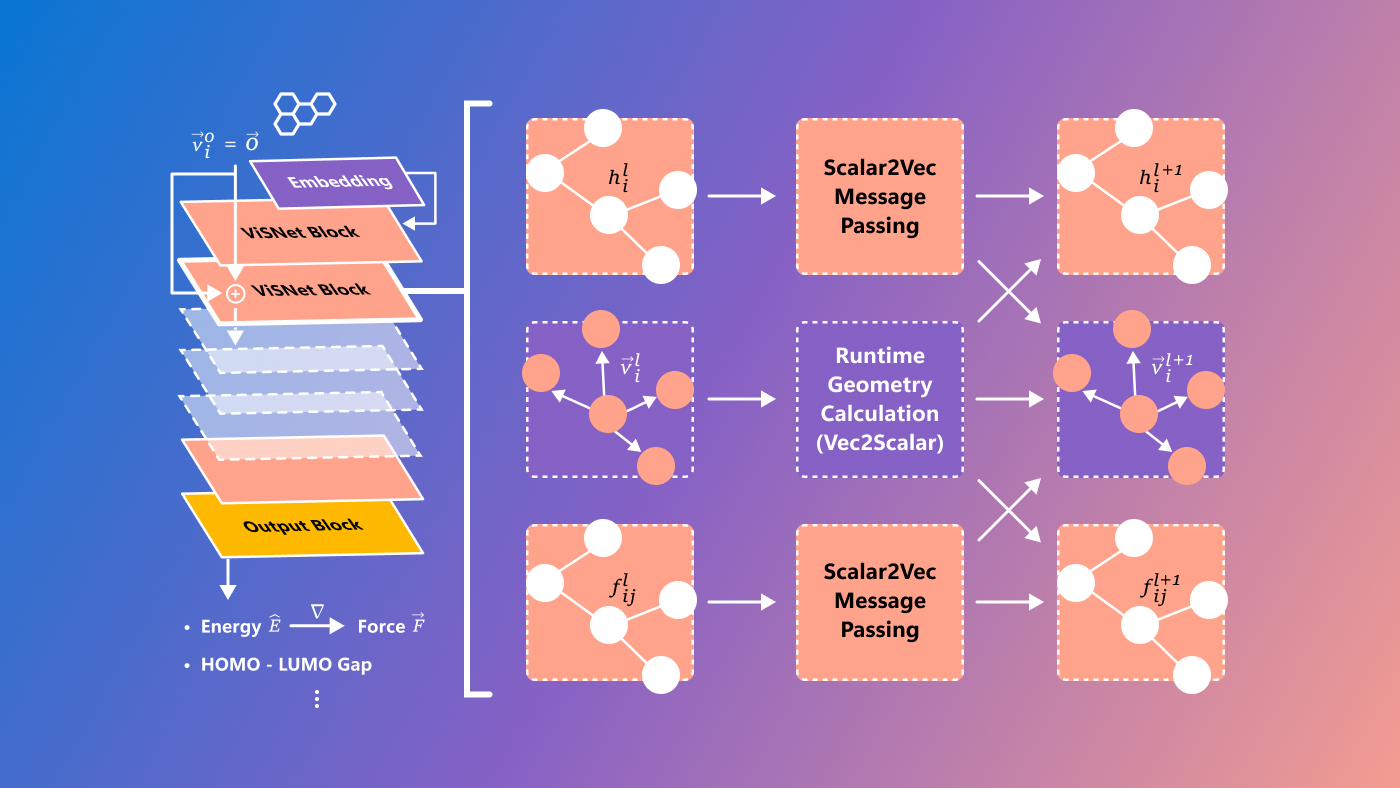
Créditos da imagem: microsoft
Investigadores da Universidade de Manchester identificam e prevêem variantes da COVID-19 através da análise de grandes conjuntos de dados genéticos relacionados com a evolução do coronavírus, em vez de estruturas puras como a ViSNet.
“A quantidade sem precedentes de dados genéticos gerados durante a pandemia requer métodos melhorados para os analisar minuciosamente”, disse o investigador principal Thomas House. “Nossa análise serve como uma prova de conceito e mostra o potencial das técnicas de aprendizado de máquina para serem usadas como uma ferramenta de alerta para a detecção precoce de grandes variantes emergentes”, disse seu colega Roberto Cahuantzi. ” ele acrescentou.
A IA também pode conceber moléculas, e muitos investigadores aderiram a iniciativas que apelam à segurança e à ética neste campo. No entanto, David Baker, um dos principais biofísicos computacionais do mundo, afirma que “os benefícios potenciais do design de proteínas superam em muito os riscos neste momento”. Como designer do AI Protein Designer, ele vai fazer Dizer. Mas ainda devemos ter cuidado com regulamentações que erram o alvo e impedem a investigação legítima, ao mesmo tempo que dão liberdade aos maus actores.
Cientistas atmosféricos da Universidade de Washington fizeram uma afirmação interessante com base numa análise de IA de 25 anos de imagens de satélite sobre o Turquemenistão. Fundamentalmente, o entendimento comummente aceite de que a turbulência económica pós-soviética levou a um declínio nas emissões pode não ser verdade; na verdade, o oposto pode estar a acontecer.

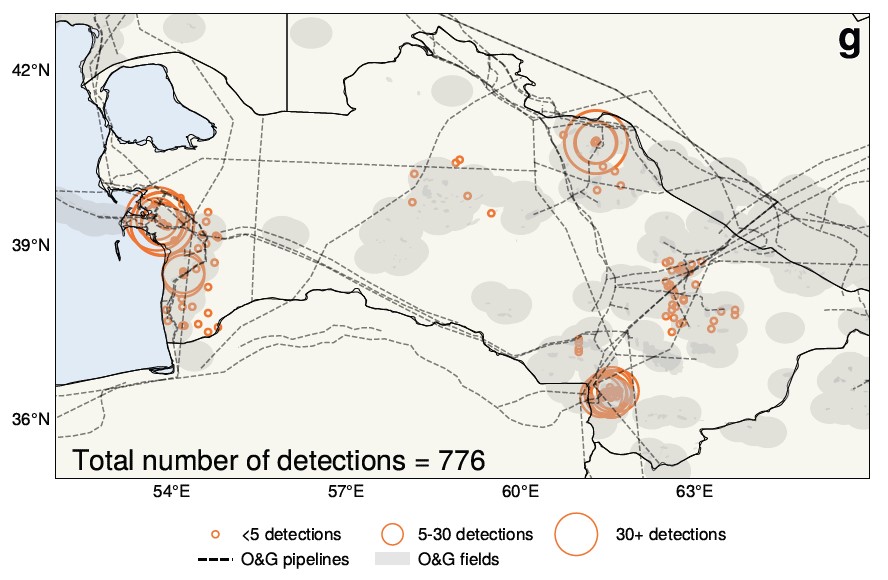
A IA ajudou a descobrir e medir o vazamento de metano mostrado aqui.
“Descobrimos que o colapso da União Soviética pareceu surpreendentemente aumentar as emissões de metano”, disse Alex Turner, professor da Universidade Estadual de Wisconsin. Os grandes conjuntos de dados e a falta de tempo para analisá-los tornaram este tópico um alvo natural para a IA, resultando nesta reversão inesperada.
Os modelos linguísticos de grande escala são treinados principalmente com dados de origem em inglês, mas isto pode impactar mais do que a sua capacidade de usar outros idiomas. Os pesquisadores da EPFL investigaram a “linguagem latente” do LlaMa-2 e descobriram que mesmo ao traduzir entre francês e chinês, o modelo parece reverter para o inglês internamente. No entanto, os investigadores sugerem que este não é apenas um processo de tradução preguiçoso; na verdade, o modelo estrutura todo o seu espaço conceptual latente em torno de conceitos e expressões inglesas. Isso importa? provavelmente. Você precisa diversificar seu conjunto de dados de qualquer maneira.